Llama 3.1 kontra GPT-4o kontra Claude 3.5: kompleksowe porównanie wiodących modeli AI



Krajobraz sztucznej inteligencji odnotował znaczące postępy wraz z wprowadzeniem najnowocześniejszych modeli językowych. Wśród wiodących modeli znajdują się Llama 3.1, GPT-4o i Claude 3.5. Każdy model oferuje unikalne możliwości i ulepszenia, odzwierciedlając trwającą ewolucję technologii AI. Przeanalizujmy te trzy wybitne modele, badając ich mocne strony, architektury i przypadki użycia.
Llama 3.1: Innowacja Open Source
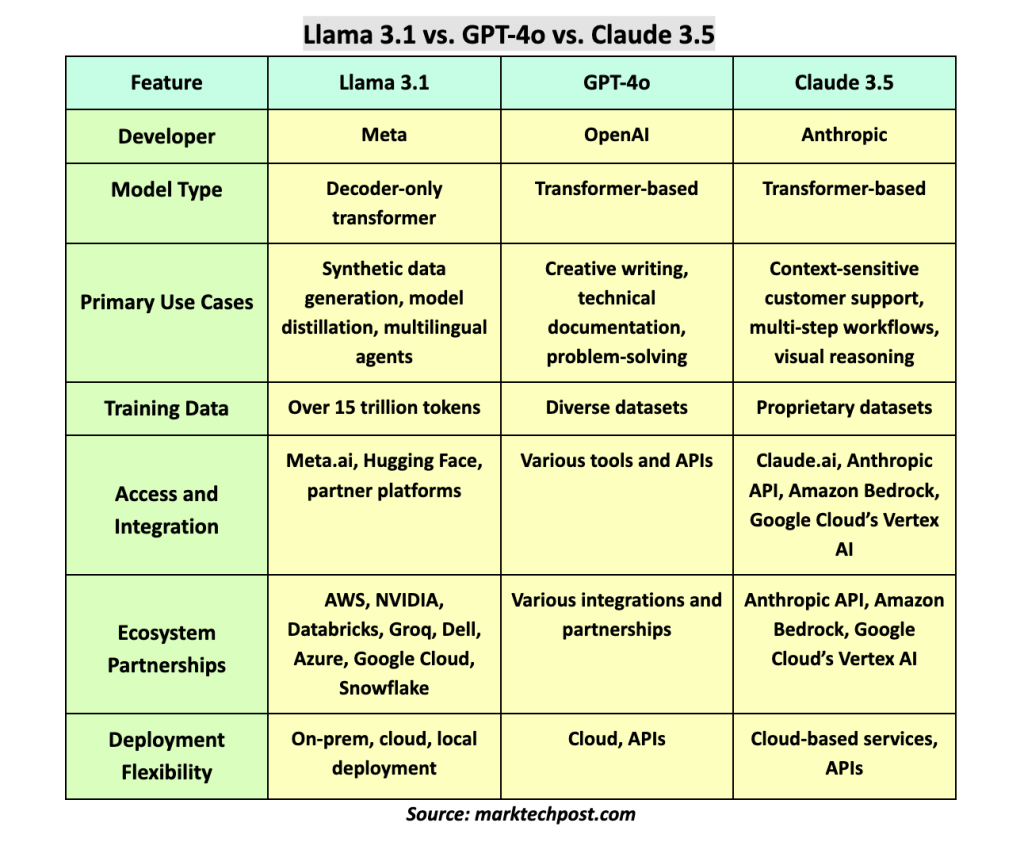
Llama 3.1, opracowana przez Meta, stanowi znaczący krok naprzód w społeczności open-source AI. Jedną z jej najbardziej niezwykłych cech jest rozszerzenie długości kontekstu do 128 KB, co umożliwia bardziej kompleksowe zrozumienie i przetwarzanie tekstu. Llama 3.1 405B, największy model w serii, oferuje niezrównaną elastyczność i najnowocześniejsze możliwości, które dorównują nawet najlepszym modelom z zamkniętym kodem źródłowym.
Architektura modelu koncentruje się na standardowym modelu transformatora dekodera z optymalizacjami skalowalności i stabilności. W połączeniu z iteracyjnymi procedurami post-treningowymi podejście to zwiększa wydajność modelu w różnych zadaniach. Llama 3.1 wyróżnia się szczególnie obsługą ośmiu języków i zdolnością do obsługi złożonych zadań, takich jak generowanie syntetycznych danych i destylacja modeli, co jest pierwszym przypadkiem w przypadku otwartej sztucznej inteligencji na taką skalę.
Jeśli chodzi o ekosystem, Meta nawiązała współpracę z głównymi graczami, takimi jak AWS, NVIDIA i Google Cloud, zapewniając dostępność i możliwość integracji Llama 3.1 na wielu platformach. Ta otwartość napędza innowacje, umożliwiając deweloperom dostosowywanie modeli do ich konkretnych potrzeb, przeprowadzanie dodatkowych dostrajań i wdrażanie w różnych środowiskach bez ograniczeń w udostępnianiu danych.
GPT-4o: Wszechstronność i Głębia
GPT-4o, wariant GPT-4 firmy OpenAI, został zaprojektowany, aby zrównoważyć wszechstronność i głębię w rozumieniu i generowaniu języka. Ten model generuje spójny, kontekstowo dokładny tekst w różnych aplikacjach, od kreatywnego pisania po dokumentację techniczną.
Architektura GPT-4o wykorzystuje mocne strony swoich poprzedników, włączając rozległe wstępne szkolenie na różnych zestawach danych, a następnie dostrajanie konkretnych zadań. W rezultacie powstaje model, który rozumie niuanse języka i łatwo dostosowuje się do różnych kontekstów. Zdolność GPT-4o do dobrego działania w różnych testach porównawczych i aplikacjach w świecie rzeczywistym podkreśla jego solidność i niezawodność jako uniwersalnego modelu językowego.
Jedną z wyróżniających się cech GPT-4o jest integracja z różnymi narzędziami i interfejsami API, co zwiększa jego funkcjonalność w praktycznych zastosowaniach. Niezależnie od tego, czy pomaga w obsłudze klienta, tworzeniu treści czy rozwiązywaniu złożonych problemów, GPT-4o zapewnia bezproblemowe doświadczenie użytkownika z wysoką dokładnością i wydajnością.
Klauzula 3.5: Prędkość i precyzja
Claude 3.5, opracowany przez Anthropic, ma na celu podniesienie standardów branżowych w zakresie inteligencji, kładąc nacisk na szybkość i precyzję. Model Claude 3.5 Sonnet, będący częścią tej serii, przewyższa swoich poprzedników i konkurentów w kilku kluczowych obszarach, w tym rozumowanie na poziomie absolwenta, biegłość w kodowaniu i obsługę złożonych instrukcji.
Claude 3.5 Sonnet działa dwa razy szybciej niż jego poprzednik, Claude 3 Opus, co czyni go idealnym do zadań wymagających szybkich czasów reakcji, takich jak kontekstowa obsługa klienta i wieloetapowe przepływy pracy. Model ten wyróżnia się również w rozumowaniu wizualnym, przewyższając poprzednie wersje w standardowych testach porównawczych widzenia i skutecznie obsługując zadania obejmujące interpretację wykresów i grafów.
Anthropic skupił się na poprawie aspektów bezpieczeństwa i prywatności Claude 3.5, włączając rygorystyczne testy i opinie zewnętrznych ekspertów. Wdrożenie modelu jest połączone z solidnymi mechanizmami bezpieczeństwa, zapewniając, że jest on mniej podatny na niewłaściwe użycie i bardziej niezawodny w krytycznych aplikacjach.
Spostrzeżenia porównawcze
Chociaż wszystkie trzy modele — Llama 3.1, GPT-4o i Claude 3.5 — stanowią znaczący postęp w dziedzinie AI, odpowiadają różnym priorytetom i przypadkom użycia. Llama 3.1 wyróżnia się otwartoźródłową naturą i szerokim wsparciem społeczności, co czyni ją wszechstronnym narzędziem dla programistów poszukujących konfigurowalnych i przejrzystych rozwiązań AI. GPT-4o oferuje zrównoważone podejście, wyróżniając się zarówno w domenach kreatywnych, jak i technicznych, i jest szeroko stosowany ze względu na swoją adaptowalność i głębię. Claude 3.5, kładący nacisk na szybkość i precyzję, jest idealny do aplikacji wymagających szybkich i dokładnych odpowiedzi, szczególnie w scenariuszach skierowanych do klienta i operacyjnych.

Podsumowując, Llama 3.1, GPT-4o i Claude 3.5 zależą w dużej mierze od konkretnych potrzeb i kontekstu użytkownika. Każdy model wnosi unikalne mocne strony, przyczyniając się do zróżnicowanego i szybko rozwijającego się pola sztucznej inteligencji. Użytkownicy są zachęcani do eksplorowania i integrowania tych modeli za pośrednictwem niezawodnych platform i partnerstw w celu uzyskania najlepszych wyników i stałego wsparcia.
Źródła


Asif Razzaq jest dyrektorem generalnym Marktechpost Media Inc. Jako wizjonerski przedsiębiorca i inżynier, Asif jest oddany wykorzystywaniu potencjału sztucznej inteligencji dla dobra społecznego. Jego najnowszym przedsięwzięciem jest uruchomienie platformy mediów sztucznej inteligencji, Marktechpost, która wyróżnia się dogłębnym omówieniem wiadomości na temat uczenia maszynowego i głębokiego uczenia, które jest zarówno technicznie solidne, jak i łatwe do zrozumienia dla szerokiej publiczności. Platforma może pochwalić się ponad 2 milionami wyświetleń miesięcznie, co ilustruje jej popularność wśród odbiorców.