Zrozumienie genetyki monogenowych zaburzeń ruchu
Zrozumienie genetyki monogenowych zaburzeń ruchu
Monogenowe zaburzenia ruchu, często rzadkie i złożone, od lat stanowią centralny punkt badań naukowych. Pionierskie strategie sekwencjonowania genomu i etapów obliczeniowej filtracji mutacji zrewolucjonizowały nasze rozumienie tych zaburzeń. Identyfikując warianty przyczynowe tych zaburzeń, badacze mogą uzyskać bezcenne spostrzeżenia, potencjalnie torując drogę innowacyjnym strategiom leczenia.
Zaawansowane technologie, takie jak sekwencjonowanie nowej generacji (NGS), sekwencjonowanie całego egzomu (WES) i sekwencjonowanie całego genomu (WGS), odegrały zasadniczą rolę w zrozumieniu zdarzeń mutacyjnych leżących u podstaw tych zaburzeń. Pozwalają na identyfikację wariantów genetycznych związanych z zaburzeniami ruchu, co stanowi znaczący krok w kierunku poznania ich genetycznych podstaw.
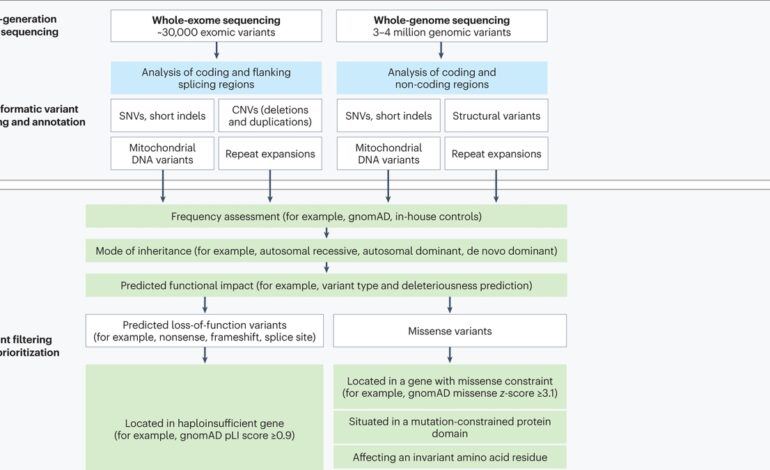
Zautomatyzowane przepływy pracy i priorytetyzacja wariantów
Interpretacja obszernych informacji o wariantach genomowych nie jest łatwym zadaniem. Obejmuje złożony proces analizy dziedziczenia i ustalania priorytetów wariantów na podstawie ich konsekwencji funkcjonalnych. Priorytetyzacja wariantów odgrywa kluczową rolę w określaniu patogeniczności zidentyfikowanych wariantów. Integracja narzędzi bioinformatycznych i wskaźników obliczeniowych uczyniła ten proces znacznie wydajniejszym i niezawodnym.
Jednakże interpretacja wariantów o niepewnym znaczeniu (VUS) stwarza poważne wyzwania. Ponadto złożoność identyfikacji wariantów przyczynowych wynikająca z heterogeniczności genetycznej i zmienności klinicznej zaburzeń ruchowych to kolejna przeszkoda, z którą często spotykają się badacze. Podkreśla to potrzebę okresowej ponownej analizy danych NGS, która może potencjalnie prowadzić do nowych odkryć i spostrzeżeń.
Rola integracji danych multiomicznych i udostępniania danych przez społeczność
Integracja danych multiomicznych to podejście wielowymiarowe, które okazało się obiecujące w zakresie optymalizacji sukcesu diagnostycznego. Integrując dane z genomiki, transkryptomiki, proteomiki i metabolomiki, badacze mogą pogłębić wiedzę na temat mechanizmu choroby, usprawniając ogólny proces diagnostyczny.
Co więcej, nie można przecenić znaczenia platform udostępniania danych i kojarzenia spraw kierowanych przez społeczność. Nie tylko ułatwiają współpracę i wymianę danych między badaczami na całym świecie, ale także przyspieszają odkrywanie nowych zależności genotyp-fenotyp. To oparte na współpracy podejście jest szczególnie korzystne w badaniach nad rzadkimi chorobami, gdzie kohorty pacjentów są często małe i rozproszone geograficznie.
Implikacje diagnostyki genetycznej
Z klinicznego punktu widzenia diagnoza genetyczna może mieć znaczący wpływ na różne aspekty opieki nad pacjentem. Może kierować interwencjami lekowymi, nadzorem i edukacją pacjentów. Ponadto może dostarczać informacji na temat badań członków rodziny, dostarczając kluczowych informacji do planowania rodziny i poradnictwa genetycznego.
W miarę odkrywania złożonej genetyki monogenowych zaburzeń ruchu, technologie medycyny precyzyjnej stają się kluczowymi narzędziami. Technologie te, w połączeniu z globalnymi wysiłkami na rzecz generowania zbiorów danych alleli specyficznych dla przodków, prawdopodobnie będą motorem kolejnej fali postępu w tej dziedzinie, dając nowe nadzieje pacjentom cierpiącym na te zaburzenia.






